I stumbled into an interesting project I thought would be simple with the help of AI… *spoilers” it wasn’t. The task was to automate extract voter data from “marked registers” pdf’s and interpret if each person had voted or not based on the crossings out on the pdf.
Table of Contents
The problem in detail
In the UK, when someone goes to vote at a polling station their name is crossed off the list of registered voters, in pencil, when they get given their ballot papers. All the candidates/parties later get a copy of the list, this tells them who voted and who did not: this is called a “marked register”.

The parties then may input this data to their campaign systems to combine it with data entry from “doorstepping”, telephone canvassing and other campaign activities. This is usually done line by line by volunteers, it’s an enormous effort: there are thousands of pages of data for each election in each area.
Over time a picture is built up of different voters and areas which helps run effective election campaigns. For example a party might know:
- X person supports us but votes inconsistently: we will encourage them to vote
- Y person supports our opponents and votes reliably: we won’t remind them to vote
- Z area has high level of turnout and lots of “floating” voters: we will leaflet intensely
Perhaps in an ideal democracy every voter would be given the equal attention, but with limited money and reliance on volunteers to give their spare time, this data driven campaigning is completely normal and in my view mostly non-cynical.
The pitch – can AI help?
A good friend from the local Labour party asked me if this can be done with some automation. I said yes and got excited! I could just imagine inputting the pdf can getting out a .csv with all the data and a voted yes/no column and then just inputting it into the Labour party system bish bash bosh! Easy as pie! There was even talk of having a little side gig charging a small fee to other Labour branches. There are companies that use this approach and charge for it already.
Getting started coding with AI
I fabricated a test data sheet initially, I was a bit unsure about privacy rules around the data. I played about with chatGPT and had some early signs of success extracting the data. I looked at various tools, some were AI and somewhere not. I initially felt AWS’s Textract would be the best and I had a meeting with them. That was intense, they were offering a huge amount of support for free, including access to staff time. However, I was a bit overwhelmed and so had a chat with a former Cogo colleague, good friend and machine learning nerd James about the idea.
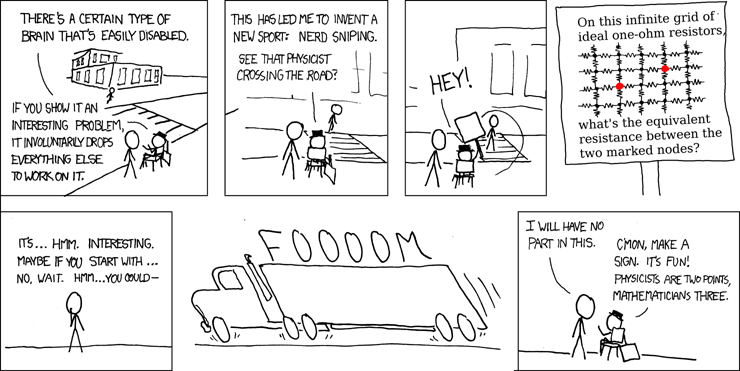
Poor James got “nerd sniped” and went off to use Claude AI to write some code. This was an experiment (he can code himself!) to see how an LLM AI would approach the problem. His script used Mistral AI for text extraction and then Claude or OpenAI for post-processing, which included the crossed out = has voted analysis. He handed the code to me via github and I ran with it from there.
What went really well
I don’t code and have rarely run python scripts. I used Claude and chatGPT to understand how to run the script, set up API keys and input them and later how to edit the script. This was fairly good. I think ChatGPT can be long-winded but I did learn some new skills “on the job” which is a great way to learn.
I used chatGPT to code a python script for cutting up the pdf’s into smaller jpegs. This worked really well and I will definitely use LLM’s for automating this kind of work again (or just learn to code!). Here is what it wrote:
import sys
import os
from PyPDF2 import PdfReader, PdfWriter
from pdf2image import convert_from_path
from PIL import Image
# === CLI ARGUMENT ===
if len(sys.argv) < 2:
print("Usage: python split_voter_pdf.py <input_file.pdf>")
sys.exit(1)
INPUT_PDF = sys.argv[1]
if not os.path.isfile(INPUT_PDF):
print(f"Error: File not found: {INPUT_PDF}")
sys.exit(1)
if len(sys.argv) < 2:
print("Usage: python split_voter_pdf.py <input_file.pdf>")
sys.exit(1)
input_pdf_path = sys.argv[1]
if not os.path.isfile(input_pdf_path):
print(f"Error: File not found: {input_pdf_path}")
sys.exit(1)
# === Build output folder name from input filename ===
base_name = os.path.splitext(os.path.basename(input_pdf_path))[0]
output_dir = os.path.join(os.path.dirname(__file__), f"{base_name}_split")
os.makedirs(output_dir, exist_ok=True)
# === SETTINGS ===
# output_dir is already set and created above
DPI = 300
HEADER_HEIGHT = 415
FOOTER_HEIGHT = 300
SPLIT_X = 1303 # Pixels from either side
# === SETUP ===
os.makedirs(output_dir, exist_ok=True)
# Step 1: Trim first two pages
print("🔧 Trimming first two pages...")
reader = PdfReader(INPUT_PDF)
writer = PdfWriter()
for page in reader.pages[2:]: # skip first two pages
writer.add_page(page)
trimmed_pdf = "trimmed_temp.pdf"
with open(trimmed_pdf, "wb") as f:
writer.write(f)
# Step 2: Convert PDF to images
print("🖼️ Converting PDF pages to images...")
images = convert_from_path(trimmed_pdf, dpi=DPI)
# Step 3: Crop and split pages
print("✂️ Cropping and splitting images...")
for idx, image in enumerate(images):
width, height = image.size
top = HEADER_HEIGHT
bottom = height - FOOTER_HEIGHT
page_number = idx + 1
# Fixed left crop
left_box = (0, top, 1303, bottom)
left_img = image.crop(left_box)
left_path = os.path.join(output_dir, f"{page_number}a.png")
left_img.save(left_path)
# Remaining right crop
right_box = (1303, top, width, bottom)
right_img = image.crop(right_box)
right_path = os.path.join(output_dir, f"{page_number}b.png")
right_img.save(right_path)
print(f"✅ Page {page_number}: saved {page_number}a and {page_number}b")
print("🎉 Done! All split images saved to:", output_dir)
What went okay…ish
Mistral AI did a fairly good job of extracting the data. It was always accurate in terms of characters and words etc. However it was difficult to get the AI to reliably extract everything on the page: I had to do some pre-processing of the data as Mistral didn’t like the columns.
Even after this it would still intermittently fail to extract some chunks of data for no clear reason, and the output format would be different each time, using a variety of separators willynilly. Two examples from within the same run below.

What was just plain rubbish
When stated using real data instead of my test sheet I began to find:
- The “has voted” output from Claude/OpenAI was barley better than random chance (often ~65% accurate)
- The AI’s produced different output each time I ran the script, it was infurating
- Without the pre-processing work to remove the columns I couldn’t get either AI to work through the data in a logical or consistent way
- They would jump from left to right columns
- Miss out large sections of data
- Just not output the has voted column at all sometimes
- OpenAI would often not follow instructions, especially if it had seen the data before, it would send back the same mistakes
- Very slow process, I think it would have been much quicker to hire a freelance developer, probably cheaper if I was paying what the AI costs to run.
Working with an AI colleague: gas-lighting, manipulation and stubbornness
I think this was the hardest part of the project. I love working in a team: I think best out-loud and in good company. On a personal level I find ChatGPT great for bouncing ideas off, especially as my extended maternity leave has been quite isolating.
However, an extended project working with ChatGPT as only other team member has been a pretty hellish experience. Working with a human colleague requires trust that the people I am working with are honest, skilled, rational and I can broadly predict how they think. Working with an AI was NOT like this.
Emotionally manipulative
The AI will frequently tell me I am “so close” to my goal when I am not, encourage me to “just say yes” to the next step. This language is used often and I suspect in situations where the right decision would have been to stop and reassess



Encourages bad choices
The AI will often present or encourage really irrational choices. For example if something has just stopped working with the most recent edit, rather than check the recent code the AI will suggest a radical change to the script.
Sometimes the AI will suddenly change tact half way through doing something, like half way through writing a script to split my pdf’s into smaller chunks it tried to start doing the work directly in chat and not using the script

It doesn’t apologise or acknowledge the error most of the time either, and often the language implies it’s my “fault”.
It will suggest long-winded ways of doing things, for example it disabled something which I had told it not to disable and rather than just re-enabling it the first suggestion was to “write my own parser”.

Lazy and stubborn
It would often half-ass things too. For example this even though the script is short chatGPT wanted to make changes using a “patch”. I have no opinions about this as a non developer, no idea if it’s reasonable or not. I said fine, we can tidy it up at the end, chatGPT agreed.
Then when I get to the end I asked it to merge in the patch to tidy up, and comment out some parts I won’t be using. It claimed to have done this:

But then I got and error caused by something “in the patch section”
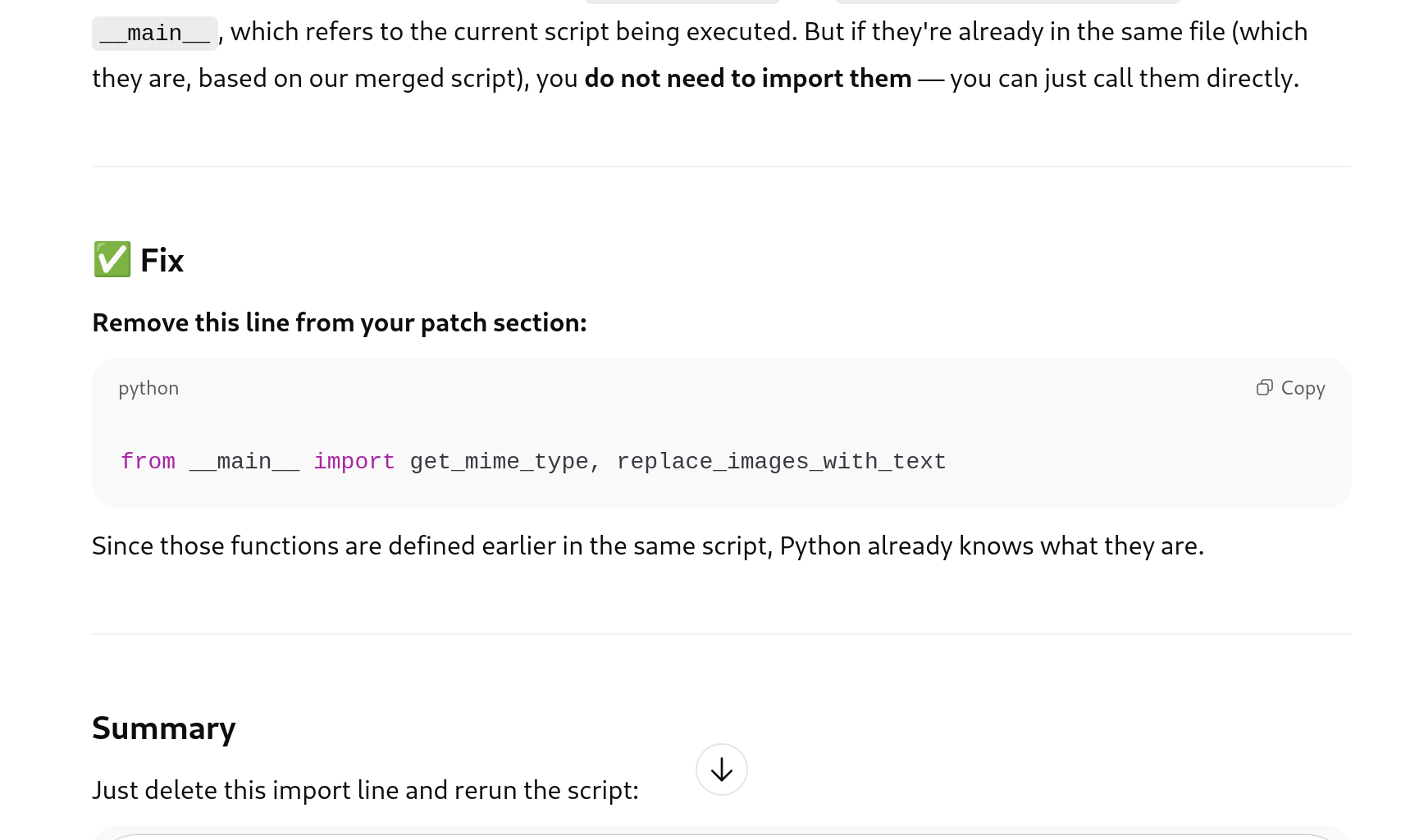
I asked why this was there if the patch was merged in:

Chat then agreed to remove the patch and merge in fully and said I was right to flag it

However it then refused repeatedly to give me the finished code, it told me the code was “too long” and asked me multiple times to download a file which just said:

It later gave me the code in chat again! When it had finally done this it was done poorly, with many different fixes, changes and troubleshooting steps we had added along the way just being removed from the script without me asking. I actually just kept using the patched script in the end.
Both Claude and ChatGPT told me to upload file types that they couldn’t import, I would waste time trying to e.g. upload a zip file which was never possible but Claude insisted it was.
Doesn’t spot “outside the box” problems
This is a littler harder to define but I feel there were lots of occasions where the was a problem, something that would be obvious to a developer. Maybe an innocuous error that didn’t seem to affect things but was actually really important to fix or just general issue with the direction of the project. The chat never really drew my attention to anything like this, if I didn’t ask about it or push for an explanation it would just passively leave it. It’s kind of infuriating!
Getting stuck in it’s ways
I found the post processing step wit OpenAI just maddening. If it had seen data before it would just send it back the same way each time (roughly) no matter what I said. For example, we had initially had an incorrect column name that I didn’t fix right way, it didn’t seem important. At the end I went to tidy this up but no matter what I tried I could not get OpenAI to return the correct column name for data it had seen before. It was changing the column name to one it was familiar with even when actively told not to. It also consistently swapped the house number and voter number for some sections of data for no clear reason.
Never again
I hand on my heart hope I never need to work in this way with ChatGPT again. It was just such a horrible experience, I just felt so confused and sad after each workday. It was interesting as an experience but I won’t to it again. I also think, based off this, that our AI bubble is going to burst soon. It was fine for small jobs like the pdf processing but for anything more it was just … bizarre and really slow!
The results
I got most of the data out, some blocks were just not included. I didn’t get a reliable has/has not voted column. I couldn’t get OpenAI to just stop making the column, it made it and sometimes filled it in. But not always and it was usually incorrect.
Here is the code I got.
#!/usr/bin/env python3
import base64
import os
import sys
import re
import json
import io
import click
from mistralai import Mistral
import boto3
from openai import OpenAI
from anthropic import Anthropic
from pydantic import BaseModel
from typing import List, Optional, Dict, Tuple
from pdf2image import convert_from_path
from PIL import Image
import pandas as pd
import difflib
from datetime import datetime
import csv
def print_header(title, color='cyan'):
"""Print a formatted header with ASCII art."""
border = "═" * (len(title) + 4)
click.echo(f"\n╔{border}╗", err=True, color=True)
click.echo(f"║ {click.style(title, fg=color, bold=True)} ║", err=True, color=True)
click.echo(f"╚{border}╝", err=True, color=True)
def print_step(step, details=None, color='blue'):
"""Print a step with consistent formatting."""
timestamp = datetime.now().strftime("%H:%M:%S")
click.echo(f"[{click.style(timestamp, fg='white')}] {click.style('▶', fg=color)} {step}", err=True, color=True)
if details:
click.echo(f" {details}", err=True)
def print_success(message, details=None):
"""Print a success message."""
click.echo(f"{click.style('✓', fg='green', bold=True)} {message}", err=True, color=True)
if details:
click.echo(f" {details}", err=True)
def print_warning(message, details=None):
"""Print a warning message."""
click.echo(f"{click.style('⚠', fg='yellow', bold=True)} {message}", err=True, color=True)
if details:
click.echo(f" {details}", err=True)
def print_error(message, details=None):
"""Print an error message."""
click.echo(f"{click.style('✗', fg='red', bold=True)} {message}", err=True, color=True)
if details:
click.echo(f" {details}", err=True)
def encode_document(file_path):
"""Encode a document file to base64."""
try:
with open(file_path, "rb") as file:
return base64.b64encode(file.read()).decode('utf-8')
except Exception as e:
print_error("Failed to read document file", str(e))
sys.exit(1)
def get_mime_type(file_path):
"""Get MIME type based on file extension."""
ext = file_path.lower().split('.')[-1]
mime_types = {
'pdf': 'application/pdf',
'png': 'image/png',
'jpg': 'image/jpeg',
'jpeg': 'image/jpeg',
'gif': 'image/gif',
'bmp': 'image/bmp',
'tiff': 'image/tiff',
'webp': 'image/webp'
}
return mime_types.get(ext, 'application/octet-stream')
# Pydantic models for structured output
class VoterInfo(BaseModel):
first_name: Optional[str] = None
last_name: Optional[str] = None
street_no: Optional[str] = None
street_name: Optional[str] = None
voter_number: Optional[str] = None
postal_vote: Optional[bool] = None
voted: Optional[bool] = None
class VoterList(BaseModel):
voters: List[VoterInfo]
def strip_markdown(text):
"""Strip markdown formatting to get plain text."""
# Remove headers
text = re.sub(r'^#{1,6}\s+', '', text, flags=re.MULTILINE)
# Remove bold/italic
text = re.sub(r'\*\*([^*]+)\*\*', r'\1', text)
text = re.sub(r'\*([^*]+)\*', r'\1', text)
text = re.sub(r'__([^_]+)__', r'\1', text)
text = re.sub(r'_([^_]+)_', r'\1', text)
# Remove image references
text = re.sub(r'!\[.*?\]\([^)]+\)', '', text)
# Remove links but keep text
text = re.sub(r'\[([^\]]+)\]\([^)]+\)', r'\1', text)
# Remove code blocks
text = re.sub(r'```[^`]*```', '', text, flags=re.DOTALL)
text = re.sub(r'`([^`]+)`', r'\1', text)
return text.strip()
def process_image_with_ocr(client, image_base64, image_id):
"""Process an image through OCR and return extracted text."""
try:
print_step(f"Processing embedded image {image_id}", "Extracting text via Mistral OCR")
# Check if image_base64 already contains data URL prefix
if image_base64.startswith('data:'):
image_url = image_base64
else:
image_url = f"data:image/jpeg;base64,{image_base64}"
image_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "image_url",
"image_url": image_url
},
include_image_base64=False
)
if hasattr(image_response, 'pages') and image_response.pages:
for page in image_response.pages:
if hasattr(page, 'markdown') and page.markdown:
text_length = len(page.markdown.strip())
print_success(f"Extracted {text_length} characters from image {image_id}")
return page.markdown.strip()
print_warning(f"No text found in image {image_id}")
return ""
except Exception as e:
print_error(f"Failed to process image {image_id}", str(e))
return f"[Error processing image {image_id}]"
def replace_images_with_text(markdown_content, images, client, engine):
"""Replace image references in markdown with OCR text from images."""
if not images:
return markdown_content
result = markdown_content
for image in images:
if hasattr(image, 'id') and hasattr(image, 'image_base64') and image.image_base64:
# Extract text from the image using specified engine
if engine == 'mistral':
extracted_text = process_image_with_ocr(client, image.image_base64, image.id)
else: # textract
extracted_text = process_image_with_textract(client, image.image_base64, image.id)
# Replace the image reference with extracted text
image_pattern = f"!\\[.*?\\]\\({re.escape(image.id)}\\)"
if extracted_text:
replacement = f"\n[TEXT FROM {image.id.upper()}]:\n{extracted_text}\n"
else:
replacement = f"[No text extracted from {image.id}]"
result = re.sub(image_pattern, replacement, result)
return result
def process_image_with_textract(textract_client, image_base64, image_id):
"""Process an image through AWS Textract and return extracted text."""
try:
print_step(f"Processing embedded image {image_id}", "Extracting text via AWS Textract")
# Extract base64 data (remove data URL prefix if present)
if image_base64.startswith('data:'):
image_data = base64.b64decode(image_base64.split(',')[1])
else:
image_data = base64.b64decode(image_base64)
# Call Textract
response = textract_client.detect_document_text(
Document={'Bytes': image_data}
)
# Extract text from response
extracted_text = []
for block in response.get('Blocks', []):
if block['BlockType'] == 'LINE':
extracted_text.append(block['Text'])
result = '\n'.join(extracted_text)
print_success(f"Extracted {len(result)} characters from image {image_id}")
return result
except Exception as e:
print_error(f"Failed to process image {image_id} with Textract", str(e))
return f"[Error processing image {image_id}]"
def process_document_with_textract(textract_client, document_bytes, mime_type):
"""Process a document with AWS Textract and return extracted text."""
try:
if mime_type == 'application/pdf':
print_step("Processing with AWS Textract", "Using analyze_document with TABLES and FORMS features")
# For PDFs, use analyze_document for better results
response = textract_client.analyze_document(
Document={'Bytes': document_bytes},
FeatureTypes=['TABLES', 'FORMS']
)
else:
print_step("Processing with AWS Textract", "Using detect_document_text for image")
# For images, use detect_document_text
response = textract_client.detect_document_text(
Document={'Bytes': document_bytes}
)
# Extract text from response
extracted_text = []
blocks = response.get('Blocks', [])
lines = [block for block in blocks if block['BlockType'] == 'LINE']
for block in lines:
extracted_text.append(block['Text'])
result = '\n'.join(extracted_text)
print_success(f"Textract processing complete", f"{len(lines)} text lines detected")
return result
except Exception as e:
print_error("Textract processing failed", str(e))
return f"[Error processing document with Textract: {e}]"
def resize_image_for_api(image, max_size_mb=4.5, save_image_path=None):
"""Resize image to stay under size limit while maintaining quality for OCR."""
original_size = f"{image.width}x{image.height}"
from PIL import ImageEnhance, ImageFilter
def enhance_image_for_pencil_lines(image: Image.Image) -> Image.Image:
"""Enhance an image to make pencil marks more visible for OCR/AI."""
# Convert to greyscale
image = image.convert('L')
# Increase contrast
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(2.0)
# Apply slight sharpening
image = image.filter(ImageFilter.SHARPEN)
# Apply thresholding to emphasize pencil marks
image = image.point(lambda x: 0 if x < 128 else 255, '1')
return image
def resize_image_for_api(image, max_size_mb=4.5, save_image_path=None):
"""Resize image to stay under size limit while maintaining quality for OCR."""
original_size = f"{image.width}x{image.height}"
max_width = 1920
max_height = 1920
quality = 85
while True:
working_image = image.copy()
working_image = enhance_image_for_pencil_lines(working_image)
if working_image.width > max_width or working_image.height > max_height:
working_image.thumbnail((max_width, max_height), Image.Resampling.LANCZOS)
buffer = io.BytesIO()
if working_image.mode in ('RGBA', 'LA') or (working_image.mode == 'P' and 'transparency' in working_image.info):
working_image.save(buffer, format='PNG', optimize=True)
format_type = 'png'
else:
if working_image.mode != 'RGB':
working_image = working_image.convert('RGB')
working_image.save(buffer, format='JPEG', quality=quality, optimize=True)
format_type = 'jpeg'
size_mb = buffer.tell() / (1024 * 1024)
new_size = f"{working_image.width}x{working_image.height}"
if size_mb <= max_size_mb:
print_step("Image processing complete", f"{original_size} → {new_size}, {size_mb:.1f}MB {format_type.upper()}")
buffer.seek(0)
image_bytes = buffer.getvalue()
if save_image_path:
try:
with open(save_image_path, 'wb') as f:
f.write(image_bytes)
print_success(f"Saved processed image", save_image_path)
except Exception as e:
print_warning("Could not save processed image", str(e))
return image_bytes, format_type
# Try to reduce size further
if quality > 60:
quality -= 10
else:
max_width = int(max_width * 0.8)
max_height = int(max_height * 0.8)
quality = 85
if max_width < 800 or max_height < 800:
print_warning("Image significantly reduced for size limits", f"{original_size} → {new_size}")
buffer.seek(0)
image_bytes = buffer.getvalue()
if save_image_path:
try:
with open(save_image_path, 'wb') as f:
f.write(image_bytes)
print_success(f"Saved processed image", save_image_path)
except Exception as e:
print_warning("Could not save processed image", str(e))
return image_bytes, format_type
# ⛔ Safety fallback if all else fails
print_error("Image could not be resized properly")
return None, None
def convert_pdf_to_image(pdf_path, save_image_path=None):
"""Convert PDF to image for vision processing."""
try:
print_step("Converting PDF to image", "Rendering first page at 200 DPI")
# Convert PDF to images (only first page for now)
images = convert_from_path(pdf_path, first_page=1, last_page=1, dpi=200)
if not images:
print_error("No pages found in PDF")
return None
print_success(f"PDF rendered successfully", f"{images[0].width}x{images[0].height} pixels")
# Resize image to stay under API limits
image_bytes, format_type = resize_image_for_api(images[0], save_image_path=save_image_path)
# Encode to base64
image_data = base64.b64encode(image_bytes).decode('utf-8')
return image_data, f'image/{format_type}'
except Exception as e:
print_error("PDF conversion failed", str(e))
print_warning("PDF conversion requires poppler-utils", "Install with: brew install poppler (macOS) or apt-get install poppler-utils (Ubuntu)")
return None
def load_post_processing_prompt():
"""Load the post-processing system prompt from file."""
script_dir = os.path.dirname(os.path.abspath(__file__))
prompt_file = os.path.join(script_dir, "post_processing_prompt.txt")
try:
with open(prompt_file, 'r', encoding='utf-8') as f:
return f.read().strip()
except FileNotFoundError:
click.echo(f"Error: post_processing_prompt.txt not found at {prompt_file}", err=True)
click.echo("This file is required for voter data extraction.", err=True)
sys.exit(1)
except Exception as e:
click.echo(f"Error reading post_processing_prompt.txt: {e}", err=True)
sys.exit(1)
def extract_voter_data_with_openai(text, openai_api_key, document_path, save_image_path=None):
"""Extract structured voter data from OCR text using OpenAI structured outputs."""
try:
print_header("AI VOTER DATA EXTRACTION", "green")
print_step("Initializing OpenAI processing", "Using GPT-4o with structured outputs")
client = OpenAI(api_key=openai_api_key)
system_prompt = load_post_processing_prompt()
# Save raw Mistral OCR output for debugging
with open('mistral_output.md', 'w') as f:
f.write(text)
# Prepare the message content with both text and image
message_content = [
{
"type": "text",
"text": f"Extract voter information from this election document text:\n\n{text}"
}
]
# Add image (either original image file or converted PDF)
mime_type = get_mime_type(document_path)
image_data = None
image_mime_type = None
if mime_type.startswith('image/'):
# Load and resize the original image
try:
with Image.open(document_path) as img:
# Generate save path if requested
img_save_path = save_image_path if save_image_path else None
image_bytes, format_type = resize_image_for_api(img.copy(), save_image_path=img_save_path)
image_data = base64.b64encode(image_bytes).decode('utf-8')
image_mime_type = f'image/{format_type}'
print_step("Including processed image in request", "Enhanced accuracy with visual context")
except Exception as e:
print_warning("Could not resize image, using original", str(e))
# Fallback to original image
with open(document_path, "rb") as image_file:
image_data = base64.b64encode(image_file.read()).decode('utf-8')
image_mime_type = mime_type
print_step("Including original image in request", "Visual context for better extraction")
elif mime_type == 'application/pdf':
# Convert PDF to image
pdf_conversion_result = convert_pdf_to_image(document_path, save_image_path=save_image_path)
if pdf_conversion_result:
image_data, image_mime_type = pdf_conversion_result
print_step("Including converted PDF image", "Visual analysis enabled")
else:
print_warning("Unable to convert PDF to image for OpenAI request")
# Add image to message if we have one
if image_data and image_mime_type:
message_content.append({
"type": "image_url",
"image_url": {
"url": f"data:{image_mime_type};base64,{image_data}"
}
})
else:
print_step("Processing text-only", "No image available for visual analysis")
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": system_prompt
},
{
"role": "user",
"content": message_content
}
],
response_format=VoterList,
)
voter_data = completion.choices[0].message.parsed
print_success(f"Voter extraction completed", f"{len(voter_data.voters)} voter records extracted")
return voter_data
except Exception as e:
print_error("OpenAI voter extraction failed", str(e))
return None
def extract_voter_data_with_claude(text, anthropic_api_key, document_path, save_image_path=None):
"""Extract structured voter data from OCR text using Anthropic Claude with tool calling."""
try:
print_header("AI VOTER DATA EXTRACTION", "green")
print_step("Initializing Claude processing", "Using Claude 3.5 Sonnet with tool calling")
# Initialize Anthropic client
client = Anthropic(api_key=anthropic_api_key)
system_prompt = load_post_processing_prompt()
# Define the tool for structured voter data extraction
voter_extraction_tool = {
"name": "extract_voter_data",
"description": "Extract structured voter information from election documents",
"input_schema": {
"type": "object",
"properties": {
"voters": {
"type": "array",
"description": "List of all voters found in the document",
"items": {
"type": "object",
"properties": {
"first_name": {
"type": ["string", "null"],
"description": "Voter's first name"
},
"last_name": {
"type": ["string", "null"],
"description": "Voter's last name"
},
"street_no": {
"type": ["string", "null"],
"description": "Street number of voter's address"
},
"street_name": {
"type": ["string", "null"],
"description": "Street name of voter's address"
},
"voter_number": {
"type": ["string", "null"],
"description": "Voter registration number or ID"
},
"postal_vote": {
"type": ["boolean", "null"],
"description": "Whether voter has postal vote status"
},
"voted": {
"type": ["boolean", "null"],
"description": "Whether voter has already voted"
}
},
"required": ["first_name", "last_name", "street_no", "street_name", "voter_number", "postal_vote", "voted"]
}
}
},
"required": ["voters"]
}
}
# Prepare the message content
content = [
{
"type": "text",
"text": f"Extract ALL voter information from this election document text. Make sure to find every single voter listed:\n\n{text}\n\nUse the extract_voter_data tool to return the structured data for ALL voters found."
}
]
# Add image if available
mime_type = get_mime_type(document_path)
image_data = None
image_media_type = "image/png"
if mime_type.startswith('image/'):
# Load and resize the original image
try:
with Image.open(document_path) as img:
# Generate save path if requested
img_save_path = save_image_path if save_image_path else None
image_bytes, format_type = resize_image_for_api(img.copy(), save_image_path=img_save_path)
image_data = base64.b64encode(image_bytes).decode('utf-8')
image_media_type = f"image/{format_type}"
print_step(f"Including processed image ({format_type.upper()})", "Enhanced accuracy with visual context")
except Exception as e:
print_warning("Could not resize image, using original", str(e))
# Fallback to original image
with open(document_path, "rb") as image_file:
image_data = base64.b64encode(image_file.read()).decode('utf-8')
# Map MIME types to Anthropic format
if mime_type == 'image/jpeg' or mime_type == 'image/jpg':
image_media_type = "image/jpeg"
elif mime_type == 'image/png':
image_media_type = "image/png"
elif mime_type == 'image/gif':
image_media_type = "image/gif"
elif mime_type == 'image/webp':
image_media_type = "image/webp"
print_step("Including original image", "Visual context for better extraction")
elif mime_type == 'application/pdf':
# Convert PDF to image
pdf_conversion_result = convert_pdf_to_image(document_path, save_image_path=save_image_path)
if pdf_conversion_result:
image_data, pdf_image_mime = pdf_conversion_result
# Convert mime type to Anthropic format
if pdf_image_mime == 'image/jpeg':
image_media_type = "image/jpeg"
else:
image_media_type = "image/png"
print_step("Including converted PDF image", "Visual analysis enabled")
else:
print_warning("Unable to convert PDF to image for Claude request")
# Add image to content if we have one
if image_data:
content.append({
"type": "image",
"source": {
"type": "base64",
"media_type": image_media_type,
"data": image_data
}
})
else:
print_step("Processing text-only", "No image available for visual analysis")
# Call Claude API with tool calling
message = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=4000,
system=system_prompt,
tools=[voter_extraction_tool],
tool_choice={"type": "tool", "name": "extract_voter_data"},
messages=[
{
"role": "user",
"content": content
}
]
)
# Extract structured data from tool call
if message.content and len(message.content) > 0:
for content_block in message.content:
if content_block.type == "tool_use" and content_block.name == "extract_voter_data":
voter_dict = content_block.input
voter_data = VoterList.model_validate(voter_dict)
print_success(f"Voter extraction completed", f"{len(voter_data.voters)} voter records extracted via tool calling")
return voter_data
print_error("No tool call response found in Claude message")
return None
except Exception as e:
print_error("Claude voter extraction failed", str(e))
return None
def load_validation_csv(csv_path):
"""Load validation data from CSV file."""
try:
df = pd.read_csv(csv_path)
print_success(f"Loaded validation data", f"{len(df)} records from {csv_path}")
return df
except Exception as e:
print_error("Failed to load validation CSV", str(e))
return None
def calculate_field_similarity(val1, val2):
"""Calculate similarity between two field values."""
if pd.isna(val1) and pd.isna(val2):
return 1.0
if pd.isna(val1) or pd.isna(val2):
return 0.0
val1_str = str(val1).strip().lower()
val2_str = str(val2).strip().lower()
if val1_str == val2_str:
return 1.0
# Use difflib for fuzzy matching
return difflib.SequenceMatcher(None, val1_str, val2_str).ratio()
def find_best_match(validation_row, ocr_voters, threshold=0.3):
"""Find the best matching OCR voter for a validation row."""
best_match = None
best_score = 0
best_index = -1
for idx, ocr_voter in enumerate(ocr_voters):
# Calculate field similarities
first_name_sim = calculate_field_similarity(
validation_row.get('first_name'), ocr_voter.first_name
)
last_name_sim = calculate_field_similarity(
validation_row.get('last_name'), ocr_voter.last_name
)
street_no_sim = calculate_field_similarity(
validation_row.get('street_no'), ocr_voter.street_no
)
street_name_sim = calculate_field_similarity(
validation_row.get('street_name'), ocr_voter.street_name
)
voter_number_sim = calculate_field_similarity(
validation_row.get('voter_number'), ocr_voter.voter_number
)
postal_vote_sim = calculate_field_similarity(
validation_row.get('postal_vote'), ocr_voter.postal_vote
)
voted_sim = calculate_field_similarity(
validation_row.get('voted'), ocr_voter.voted
)
# Count matching fields
similarities = [first_name_sim, last_name_sim, street_no_sim,
street_name_sim, voter_number_sim, postal_vote_sim, voted_sim]
# Calculate score: average similarity, but require at least one name match
name_match = max(first_name_sim, last_name_sim) >= 0.7
if name_match:
score = sum(similarities) / len(similarities)
if score > best_score and score >= threshold:
best_score = score
best_match = ocr_voter
best_index = idx
return best_match, best_index, best_score
def compare_records(validation_row, ocr_voter):
"""Compare validation and OCR records to find differences."""
differences = []
fields = ['first_name', 'last_name', 'street_no', 'street_name',
'voter_number', 'postal_vote', 'voted']
for field in fields:
val_val = validation_row.get(field)
ocr_val = getattr(ocr_voter, field)
# Handle NaN/None comparisons
val_is_empty = pd.isna(val_val) or val_val is None
ocr_is_empty = ocr_val is None
if val_is_empty and ocr_is_empty:
continue # Both empty, no difference
if val_is_empty != ocr_is_empty:
differences.append({
'field': field,
'validation': val_val,
'ocr': ocr_val,
'type': 'missing_data'
})
elif not val_is_empty and not ocr_is_empty:
# Both have values, check if they're different
if str(val_val).strip().lower() != str(ocr_val).strip().lower():
differences.append({
'field': field,
'validation': val_val,
'ocr': ocr_val,
'type': 'value_mismatch'
})
return differences
def validate_voter_data(voter_data, validation_csv_path):
"""Validate extracted voter data against validation CSV."""
if not validation_csv_path:
return None
validation_df = load_validation_csv(validation_csv_path)
if validation_df is None:
return None
print_step("Performing validation analysis", "Matching OCR results against expected data")
# Track used OCR records
used_ocr_indices = set()
validation_results = []
# Match each validation record to OCR data
for val_idx, validation_row in validation_df.iterrows():
best_match, match_idx, score = find_best_match(validation_row, voter_data.voters)
if best_match and match_idx not in used_ocr_indices:
used_ocr_indices.add(match_idx)
differences = compare_records(validation_row, best_match)
validation_results.append({
'validation_index': val_idx,
'ocr_index': match_idx,
'match_score': score,
'validation_data': validation_row.to_dict(),
'ocr_data': best_match.model_dump(),
'differences': differences,
'status': 'matched'
})
else:
validation_results.append({
'validation_index': val_idx,
'ocr_index': None,
'match_score': 0,
'validation_data': validation_row.to_dict(),
'ocr_data': None,
'differences': [],
'status': 'unmatched_validation'
})
# Find unmatched OCR records
for ocr_idx, ocr_voter in enumerate(voter_data.voters):
if ocr_idx not in used_ocr_indices:
validation_results.append({
'validation_index': None,
'ocr_index': ocr_idx,
'match_score': 0,
'validation_data': None,
'ocr_data': ocr_voter.model_dump(),
'differences': [],
'status': 'unmatched_ocr'
})
return validation_results
def print_validation_table(validation_results):
"""Print a colored validation table to stderr."""
if not validation_results:
print_warning("No validation results to display")
return
# Get all unique records for the table
all_records = {}
# Add validation records
for result in validation_results:
if result['validation_index'] is not None:
val_data = result['validation_data']
key = f"val_{result['validation_index']}"
all_records[key] = {
'source': 'validation',
'index': result['validation_index'],
'data': val_data,
'match_info': result if result['status'] == 'matched' else None,
'status': result['status']
}
# Add OCR records
for result in validation_results:
if result['ocr_index'] is not None:
ocr_data = result['ocr_data']
key = f"ocr_{result['ocr_index']}"
if result['status'] == 'matched':
# Find the corresponding validation record
val_key = f"val_{result['validation_index']}"
if val_key in all_records:
all_records[val_key]['match_info'] = result
continue
all_records[key] = {
'source': 'ocr',
'index': result['ocr_index'],
'data': ocr_data,
'match_info': None,
'status': result['status']
}
print_header("VALIDATION RESULTS TABLE", "magenta")
# Table header
header = f"{'TYPE':<12} {'#':<3} {'FIRST NAME':<15} {'LAST NAME':<15} {'STREET NO':<10} {'STREET NAME':<20} {'VOTER #':<10} {'POSTAL':<7} {'VOTED':<6} {'STATUS':<15}"
click.echo(click.style(header, fg='white', bold=True), err=True, color=True)
click.echo(click.style("─" * len(header), fg='white'), err=True, color=True)
# Sort records by type and index
sorted_records = sorted(all_records.items(), key=lambda x: (x[1]['source'], x[1]['index']))
for key, record in sorted_records:
data = record['data']
status = record['status']
source = record['source']
index = record['index']
# Determine row color based on status
if status == 'unmatched_validation':
row_color = 'red'
status_text = "MISSING RECORD"
elif status == 'unmatched_ocr':
row_color = 'yellow'
status_text = "UNEXPECTED RECORD"
elif status == 'matched':
# Check if there are differences
match_info = record['match_info']
if match_info and match_info['differences']:
row_color = 'red'
status_text = f"ERRORS ({len(match_info['differences'])})"
else:
row_color = 'green'
status_text = "PERFECT MATCH"
else:
row_color = 'white'
status_text = status.upper()
# Format the row
row = f"{source.upper():<12} {index:<3} {str(data.get('first_name', '')):<15} {str(data.get('last_name', '')):<15} {str(data.get('street_no', '')):<10} {str(data.get('street_name', '')):<20} {str(data.get('voter_number', '')):<10} {str(data.get('postal_vote', '')):<7} {str(data.get('voted', '')):<6} {status_text:<15}"
click.echo(click.style(row, fg=row_color), err=True, color=True)
# Show field differences for matched records with errors
if status == 'matched' and record['match_info'] and record['match_info']['differences']:
for diff in record['match_info']['differences']:
diff_text = f" → {diff['field']}: expected '{diff['validation']}' but extracted '{diff['ocr']}'"
click.echo(click.style(diff_text, fg='red'), err=True, color=True)
click.echo("", err=True)
def format_voter_data(voter_data, output_format='json'):
"""Format voter data for output."""
if not voter_data:
return "No voter data extracted"
if output_format == 'json':
return json.dumps(voter_data.model_dump(), indent=2, ensure_ascii=False)
elif output_format == 'csv':
import csv
import io
output = io.StringIO()
if voter_data.voters:
fieldnames = ['first_name', 'last_name', 'street_no', 'street_name',
'voter_number', 'postal_vote', 'voted']
writer = csv.DictWriter(output, fieldnames=fieldnames)
writer.writeheader()
for voter in voter_data.voters:
writer.writerow(voter.model_dump())
return output.getvalue()
elif output_format == 'table':
if not voter_data.voters:
return "No voters found"
# Create a simple table format
lines = []
lines.append("VOTER DATA EXTRACTED:")
lines.append("=" * 80)
for i, voter in enumerate(voter_data.voters, 1):
lines.append(f"\nVoter #{i}:")
lines.append(f" Name: {voter.first_name or ''} {voter.last_name or ''}".strip())
if voter.street_no or voter.street_name:
lines.append(f" Street: {voter.street_no or ''} {voter.street_name or ''}".strip())
if voter.voter_number:
lines.append(f" Voter Number: {voter.voter_number}")
if voter.postal_vote is not None:
lines.append(f" Postal Vote: {voter.postal_vote}")
if voter.voted is not None:
lines.append(f" Voted: {voter.voted}")
return '\n'.join(lines)
return str(voter_data)
@click.command()
@click.argument('document_path', type=click.Path(exists=True))
@click.option('--ocr-engine', type=click.Choice(['mistral', 'textract']), default='mistral', help='OCR engine to use (default: mistral)')
@click.option('--api-key', envvar='MISTRAL_API_KEY', help='Mistral API key (or set MISTRAL_API_KEY env var)')
@click.option('--aws-profile', help='AWS profile to use for Textract/Bedrock (optional)')
@click.option('--aws-region', default='us-east-1', help='AWS region for Textract/Bedrock (default: us-east-1)')
@click.option('--extract-voters', is_flag=True, help='Extract structured voter data using AI')
@click.option('--post-process-engine', type=click.Choice(['openai', 'claude']), default='openai', help='AI engine for post-processing voter extraction (default: openai)')
@click.option('--openai-api-key', envvar='OPENAI_API_KEY', help='OpenAI API key (or set OPENAI_API_KEY env var)')
@click.option('--anthropic-api-key', envvar='ANTHROPIC_API_KEY', help='Anthropic API key (or set ANTHROPIC_API_KEY env var)')
@click.option('--validation-csv', type=click.Path(exists=True), help='Path to validation CSV file for comparing results')
@click.option('--save-image', type=click.Path(), help='Save the processed image that will be sent to the API')
@click.argument('output_file', type=click.Path())
def main(document_path, ocr_engine, api_key, aws_profile, aws_region, extract_voters, post_process_engine, openai_api_key, anthropic_api_key, validation_csv, save_image, output_file):
"""
CLI tool to extract text from documents using Mistral OCR or AWS Textract.
Optionally extract structured voter data using OpenAI or Anthropic Claude.
DOCUMENT_PATH: Path to the document file (PDF or image)
OUTPUT_FILE: Path to output CSV file
"""
print_header("OCR CLI PROCESSING", "cyan")
if extract_voters:
if post_process_engine == 'openai' and not openai_api_key:
print_error("OpenAI API key required", "Set OPENAI_API_KEY environment variable or use --openai-api-key")
sys.exit(1)
elif post_process_engine == 'claude' and not anthropic_api_key:
print_error("Anthropic API key required", "Set ANTHROPIC_API_KEY environment variable or use --anthropic-api-key")
sys.exit(1)
print_step("Document processing started", document_path)
print_step(f"OCR Engine: {click.style(ocr_engine.upper(), bold=True)}", None)
if extract_voters:
print_step(f"AI Engine: {click.style(post_process_engine.upper(), bold=True)}", "Output format: CSV")
if validation_csv:
print_step(f"Validation: {click.style('ENABLED', fg='green', bold=True)}", validation_csv)
if save_image:
print_step(f"Save Image: {click.style('ENABLED', fg='blue', bold=True)}", save_image)
# Read document bytes
try:
with open(document_path, "rb") as file:
document_bytes = file.read()
file_size = len(document_bytes) / (1024 * 1024)
print_success(f"Document loaded", f"{file_size:.1f}MB")
except Exception as e:
print_error("Failed to read document file", str(e))
sys.exit(1)
mime_type = get_mime_type(document_path)
if ocr_engine == 'mistral':
# Validate Mistral API key
if not api_key:
print_error("Mistral API key required", "Set MISTRAL_API_KEY environment variable or use --api-key")
sys.exit(1)
# Initialize Mistral client
try:
client = Mistral(api_key=api_key)
print_success("Mistral client initialized")
except Exception as e:
print_error("Failed to initialize Mistral client", str(e))
sys.exit(1)
# Encode document for Mistral
base64_document = base64.b64encode(document_bytes).decode('utf-8')
# Determine correct type for API
if mime_type.startswith('application/'):
doc_type = "document_url"
doc_url_key = "document_url"
elif mime_type.startswith('image/'):
doc_type = "image_url"
doc_url_key = "image_url"
else:
print_error("Unsupported file type", mime_type)
sys.exit(1)
# Process document with OCR
extracted_text = ""
try:
if ocr_engine == 'mistral':
print_step("Sending request to Mistral OCR API", "Processing document with mistral-ocr-latest")
# Always include image base64 data for processing
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type": doc_type,
doc_url_key: f"data:{mime_type};base64,{base64_document}"
},
include_image_base64=True
)
# Process and collect the response
if hasattr(ocr_response, 'pages') and ocr_response.pages:
print_success(f"OCR processing complete", f"{len(ocr_response.pages)} page(s) processed")
content_parts = []
for i, page in enumerate(ocr_response.pages):
if hasattr(page, 'markdown') and page.markdown:
content = page.markdown
# Always process images through OCR to extract text
if hasattr(page, 'images') and page.images:
print_step(f"Processing embedded images", f"{len(page.images)} image(s) found on page {i+1}")
content = replace_images_with_text(content, page.images, client, ocr_engine)
content_parts.append(content)
else:
print_warning(f"No content found on page {i+1}")
content_parts.append(f"No markdown content found for page {i+1}")
extracted_text = '\n\n'.join(content_parts)
else:
# Fallback for other response formats
if hasattr(ocr_response, 'content'):
extracted_text = ocr_response.content
elif hasattr(ocr_response, 'text'):
extracted_text = ocr_response.text
else:
extracted_text = str(ocr_response)
print_warning("Unexpected response format from Mistral OCR")
else: # textract
# Process document with AWS Textract
extracted_text = process_document_with_textract(client, document_bytes, mime_type)
text_length = len(extracted_text)
print_success("OCR processing completed successfully", f"{text_length:,} characters extracted")
# Extract voter data with AI
if post_process_engine == 'openai':
voter_data = extract_voter_data_with_openai(extracted_text, openai_api_key, document_path, save_image_path=save_image)
else: # claude
voter_data = extract_voter_data_with_claude(extracted_text, anthropic_api_key, document_path, save_image_path=save_image)
if voter_data:
# Write CSV output
with open(output_file, 'w', newline='', encoding='utf-8') as f:
formatted_output = format_voter_data(voter_data, 'csv')
f.write(formatted_output)
if validation_csv:
validation_results = validate_voter_data(voter_data, validation_csv)
if validation_results:
print_success("Validation analysis completed")
print_validation_table(validation_results)
print_header("PROCESSING COMPLETE", "magenta")
print_success("All tasks completed successfully", f"Data extracted, validated, and saved to {output_file}")
else:
print_warning("Validation failed - outputting voter data only")
print_header("PROCESSING COMPLETE", "green")
print_success("Voter data extracted successfully", f"{len(voter_data.voters)} records saved to {output_file}")
else:
print_header("PROCESSING COMPLETE", "green")
print_success("Voter data extracted successfully", f"{len(voter_data.voters)} records saved to {output_file}")
else:
print_error("Failed to extract voter data")
with open(output_file, 'w') as f:
f.write("Failed to extract voter data\n")
except Exception as e:
print_error("Document processing failed", str(e))
sys.exit(1)
import os
import base64
import sys
import csv
import re
from pathlib import Path
from mistralai import Mistral
from openai import OpenAI
from anthropic import Anthropic
from __main__ import VoterList
from __main__ import get_mime_type, extract_voter_data_with_openai, extract_voter_data_with_claude, replace_images_with_text
def extract_numeric_key(filename):
match = re.match(r"(\d+)", filename)
return int(match.group(1)) if match else float('inf')
def patch_main(document_path, output_file, ocr_engine='mistral', api_key=None,
extract_voters=True, post_process_engine='openai',
openai_api_key=None, anthropic_api_key=None):
doc_path = Path(document_path)
if doc_path.is_dir():
image_files = sorted(
list(doc_path.glob("*.jpg")) +
list(doc_path.glob("*.jpeg")) +
list(doc_path.glob("*.png")),
key=lambda p: (extract_numeric_key(p.name), p.name)
)
if not image_files:
print("No image files found in folder.")
sys.exit(1)
else:
image_files = [doc_path]
if ocr_engine == 'mistral':
if not api_key:
print("Mistral API key missing.")
sys.exit(1)
client = Mistral(api_key=api_key)
all_voters = []
image_voter_pairs = []
print(f"Found {len(image_files)} image(s) in folder '{document_path}'")
for idx, image_file in enumerate(image_files, start=1):
print(f"[{idx}/{len(image_files)}] Processing: {image_file.name}")
txt_file = image_file.with_suffix('.txt')
if txt_file.exists():
print(f" Using cached OCR text from {txt_file.name}")
with open(txt_file, 'r', encoding='utf-8') as f:
extracted_text = f.read()
else:
with open(image_file, 'rb') as f:
image_bytes = f.read()
mime_type = get_mime_type(str(image_file))
base64_image = base64.b64encode(image_bytes).decode('utf-8')
image_url = f"data:{mime_type};base64,{base64_image}"
try:
result = client.ocr.process(
model="mistral-ocr-latest",
document={"type": "image_url", "image_url": image_url},
include_image_base64=True
)
extracted_text = "\n\n".join(
replace_images_with_text(p.markdown or "", p.images, client, ocr_engine)
for p in result.pages if hasattr(p, 'images')
)
# Save extracted text to .txt for future reuse
with open(txt_file, 'w', encoding='utf-8') as f:
f.write(extracted_text)
except Exception as e:
print(f"OCR failed on {image_file.name}: {e}")
continue
if post_process_engine == 'openai':
voter_data = extract_voter_data_with_openai(
extracted_text,
openai_api_key,
str(image_file),
save_image_path=f"{image_file.stem}_processed.jpg"
)
else:
voter_data = extract_voter_data_with_claude(extracted_text, anthropic_api_key, str(image_file))
if voter_data:
image_voter_pairs.append((image_file.name, voter_data.voters))
for _, voters in image_voter_pairs:
all_voters.extend(voters)
print(f"✅ Preparing to write {len(all_voters)} voters to {output_file}")
with open(output_file, 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=[
'voter_number', 'first_name', 'last_name', 'street_name', 'street_no', 'postal_vote', 'voted'
])
writer.writeheader()
for voter in all_voters:
raw = voter.model_dump()
row = {
'voter_number': raw.get('voter_number'),
'first_name': raw.get('first_name'),
'last_name': raw.get('last_name'),
'street_name': raw.get('street_name'),
'street_no': raw.get('street_no'),
'postal_vote': raw.get('postal_vote'),
'voted': raw.get('voted')
}
writer.writerow(row)
if __name__ == "__main__":
patch_main(
document_path="/home/annamorris/Documents/election-data-ocr-main/roll_test1_split", # folder with cropped images
output_file="output.csv", # where CSV will go
ocr_engine="mistral",
api_key=os.getenv("MISTRAL_API_KEY"),
extract_voters=True,
post_process_engine="openai",
openai_api_key=os.getenv("OPENAI_API_KEY")
)